🌍 News
- [2025/01/22] WMA Web Agent is accepted by ICLR 2025!
- [2024/06/12] WMA Web Agent is out!
Large language models (LLMs) have recently gained much attention in building autonomous agents. However, the performance of current LLM-based web agents in long-horizon tasks is far from optimal, often yielding errors such as repeatedly buying a non-refundable flight ticket. By contrast, humans can avoid such an irreversible mistake, as we have an awareness of the potential outcomes (e.g., losing money) of our actions, also known as the "world model". Motivated by this, our study first starts with preliminary analyses, confirming the absence of world models in current LLMs (e.g., GPT-4, Claude-3.5-Sonnet, etc.). Then, we present a World-Model-Augmented (WMA) web agent, which simulates the outcomes of its actions for better decision-making. To overcome the challenges in training LLMs as world models predicting next observations, such as repeated elements across observations and long HTML inputs, we propose a transition-focused observation abstraction, where the prediction objectives are free-form natural language descriptions exclusively highlighting important state differences between time steps. Experiments on WebArena and Mind2Web show that our world models improve agents' policy selection without training and demonstrate our agents' cost- and time-efficiency compared to recent tree-search-based agents.

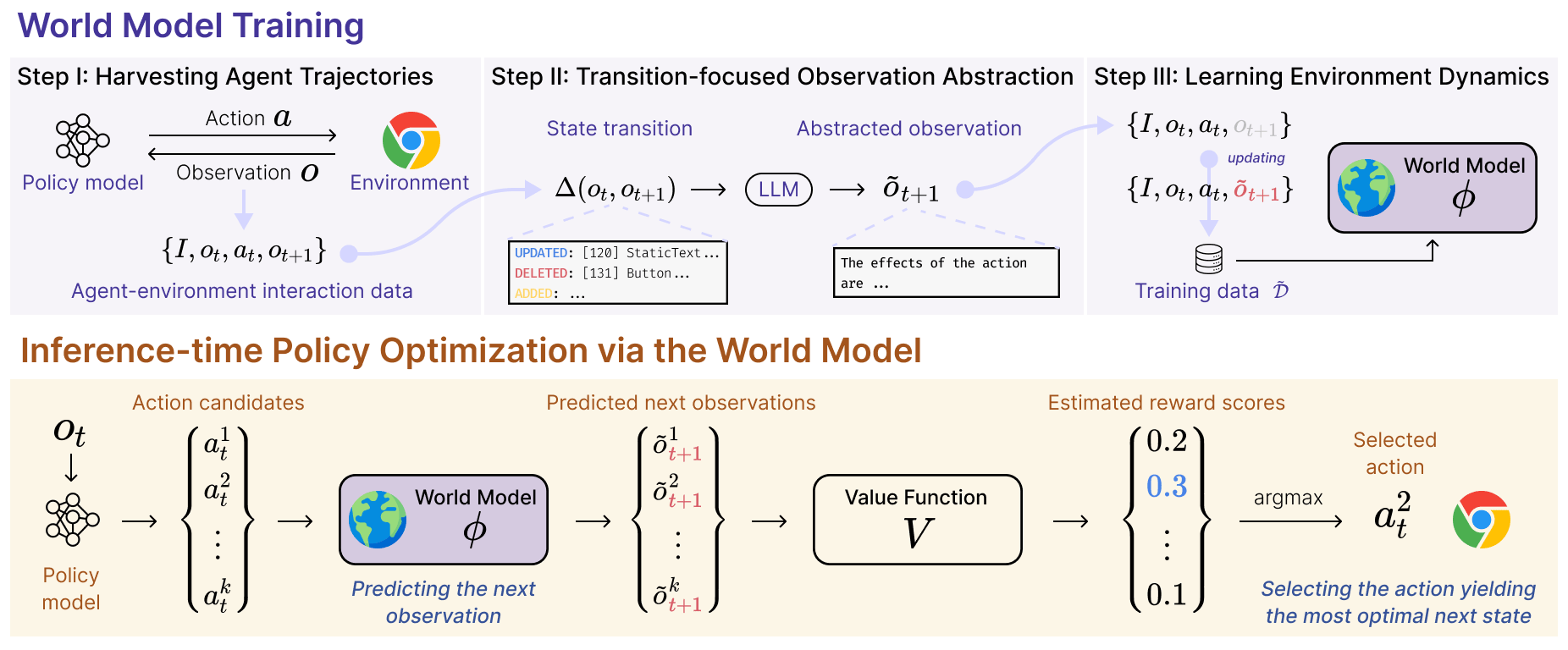
We start by collecting the dataset \( \mathcal{D} = \sum^{n}_{t=1} \{ I, o_t, a_t, o_{t+1} \} \) from the environment \( \mathcal{E} \) for training world models. For that, we prompt an LLM as a web agent to achieve the goal provided in the user instruction \( I \), by iteratively predicting an action \( a_t \) based on the current observation \( o_t \) throughout all \( n \) time steps. Consequently, we obtain \( \mathcal{D} \) from trajectory \( \tau = \{o_1, a_1, o_2, ..., a_{n}, o_{n+1}\} \) based on \( I \), and environment states of \( n \) time steps \( \{s_1, ..., s_{n+1}\} \subset \mathcal{S} \) obtained via transition function \( \mathcal{T} \).
With the collected data \( \mathcal{D} = \sum^{n}_{t=1} \{ I, o_t, a_t, o_{t+1} \} \), it is intuitive to train LLM-based world models to predict \( o_{t+1} \), which is expressed with texts (e.g., HTML and accessibility tree).
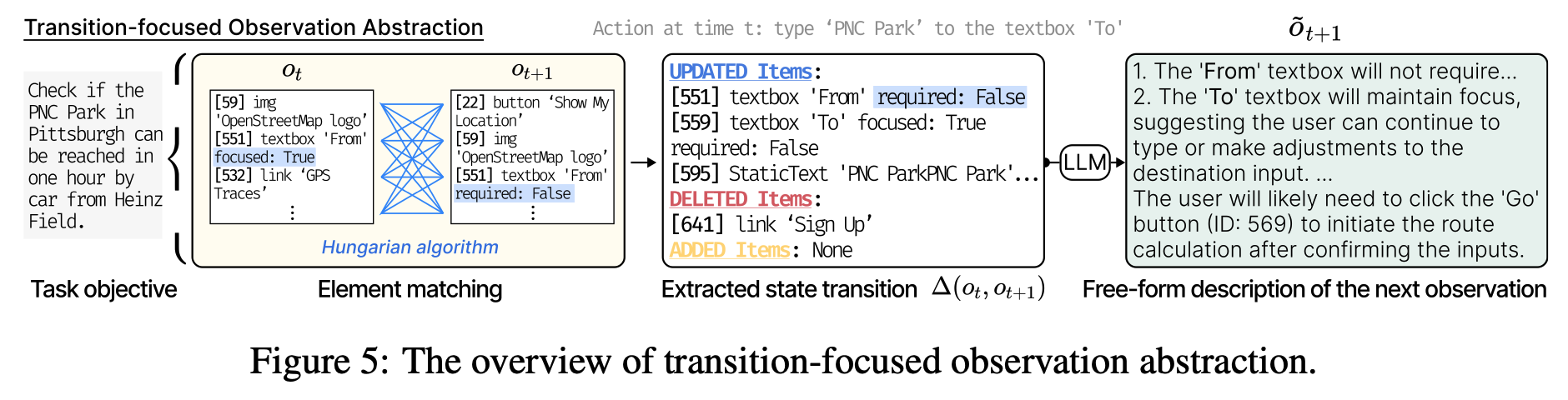
As shown in Figure 5, we first (i) apply the Hungarian algorithm
to calculate a cost matrix for matching elements between
\( o_t \) and \( o_{t+1} \) and (ii) mechanically transform the results into a list of state transition
\( \Delta(o_t, o_{t+1}) \), pointing out UPDATED, DELETED, and ADDED elements on the web.
After that, we prompt an LLM to convert the extracted \( \Delta(o_t, o_{t+1}) \) into a free-form natural language
description \( \tilde{o}_{t+1} \), which highlights the difference between the new observation \( o_{t+1} \) and \( o_t \).
Replacing \( o_{t+1} \) in
\( \mathcal{D} = \{ I, o_t, a_t, o_{t+1} \} \) collected in Step I with \( \tilde{o}_{t+1} \) we just acquired here,
we get a final dataset
\( \tilde{\mathcal{D}} = \sum^{n}_{t=1} \{ I, o_t, a_t, \tilde{o}_{t+1} \} \)
for training world models.
Lastly, using \( \tilde{\mathcal{D}} \), we proceed to train the internal world model \( \phi \) of the web agent to learn the environment dynamics. Formally, an LLM working as the world model is trained to predict the abstracted observation \( \tilde{o} \) of the next state \( s_{t+1} \), given three inputs: the user instruction \( I \), the current observation \( o_t \), and the current action \( a_t \). This LLM is trained to minimize the following loss term via the next-token prediction objective:
\[ \mathcal{L}_{\phi} = -\log \sum_{(\tilde{o}, o, a, I) \in \tilde{\mathcal{D}}} p(\tilde{o}_{t+1}| o_t, a_t, I) \]
For evaluation, we use the official WebArena and Mind2Web benchmarks. WebArena includes 812 real-life tasks in simulated environments across five different websites, spanning four key domains - e-commerce (Shopping), social forums (Reddit), collaborative software development (Gitlab), content manage- ment (CMS), and Map. The main metric, Success Rate (SR), is calculated as the percentage of the user instructions that are success- fully accomplished by the generated agent trajectory. On the other hand, Mind2Web covers over 2,000 open-ended tasks, collected from 137 websites of 31 domains and crowd- sourced action sequences for the tasks. Along with the SR, Mind2Web also uses Step SR, which measures whether the predicted action selects both the correct action type (action F1) and element ID (element accuracy). When the agent succeeds in all steps in a trajectory, it is evaluated as success.
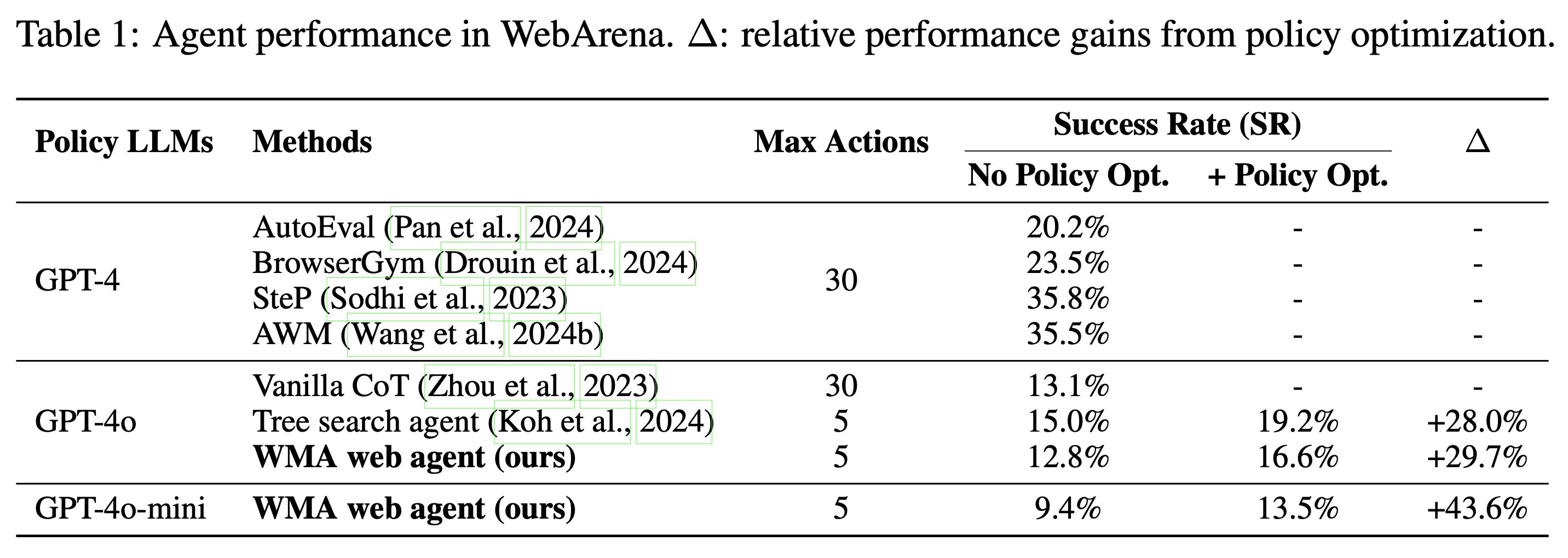
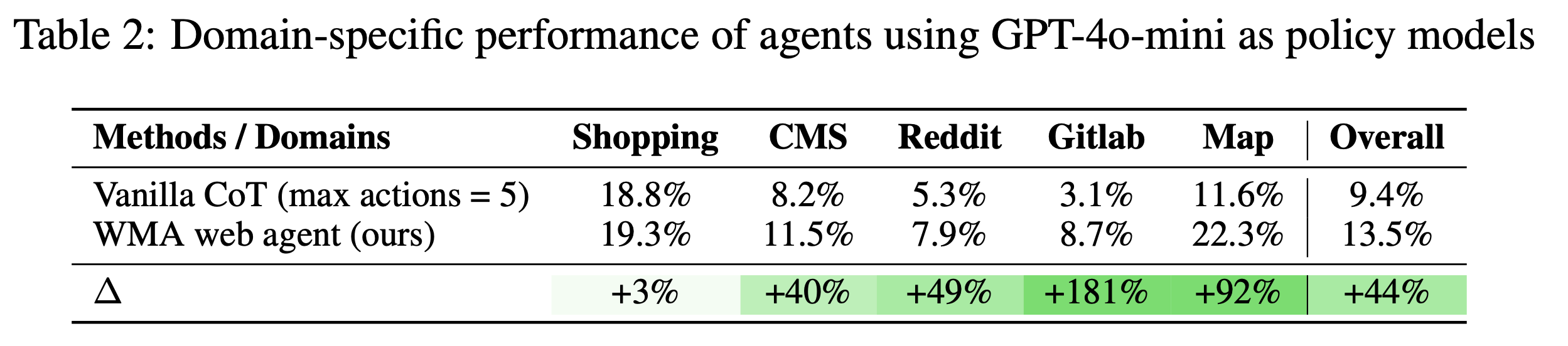
From our experiments in Table 1 and Table 2, we observed the following results:
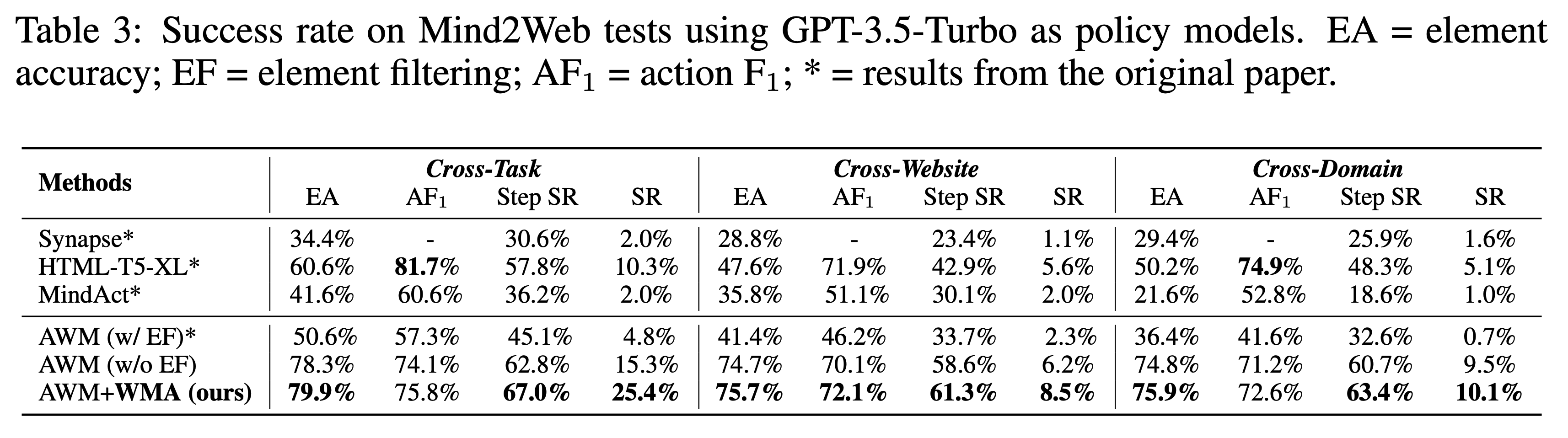
From our experiments in Table 3, we observed the following results:

We conduct several ablation studies on our WMA web agent with 200 randomly sampled instances from WebArena (Shopping: 50; Gitlab: 50; Map: 100). We use GPT-4o-mini as policy models.

We observe the following findings in Table 5:

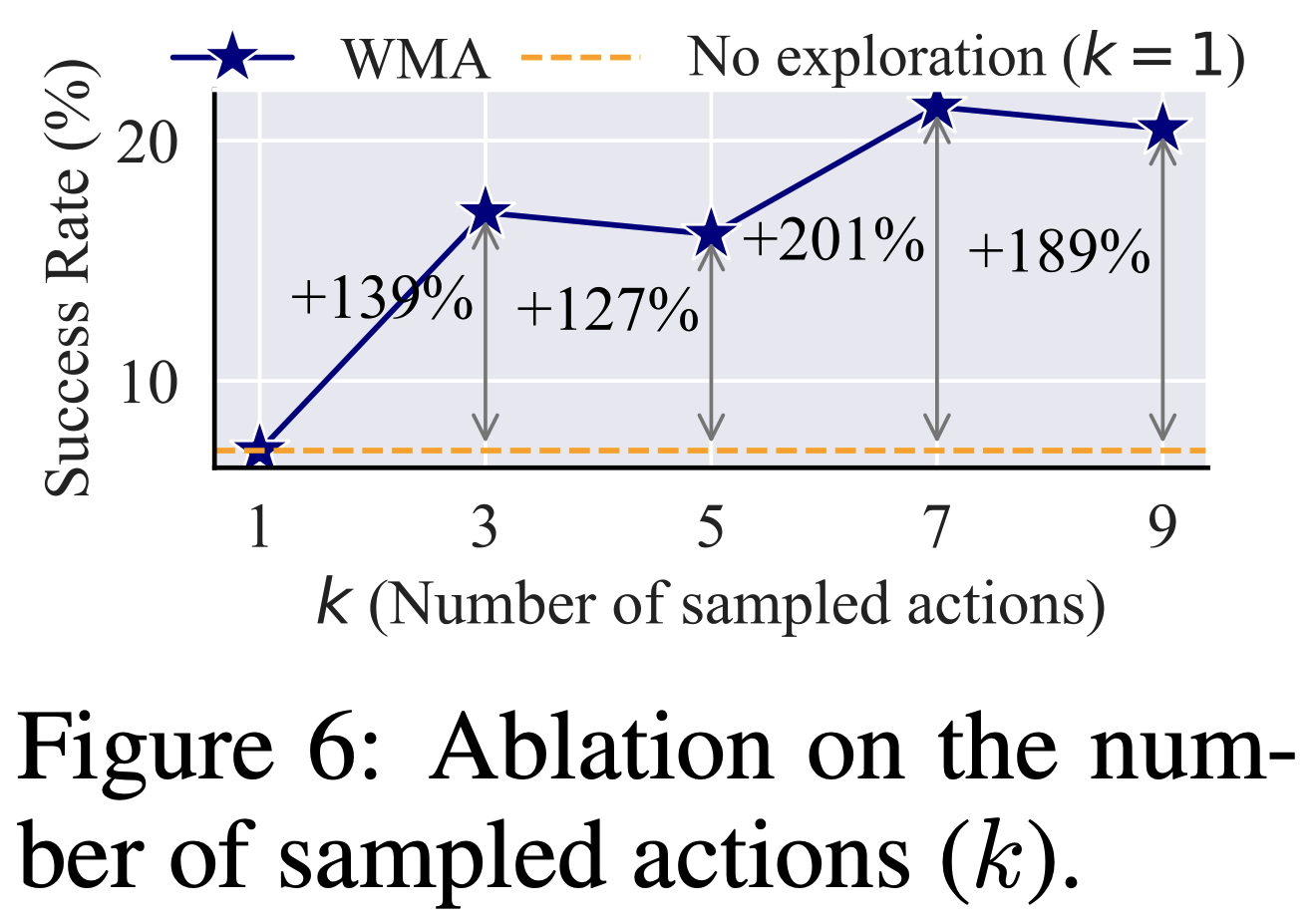
Additionally, we reveal the following findings in Table 6 and Figure 6:
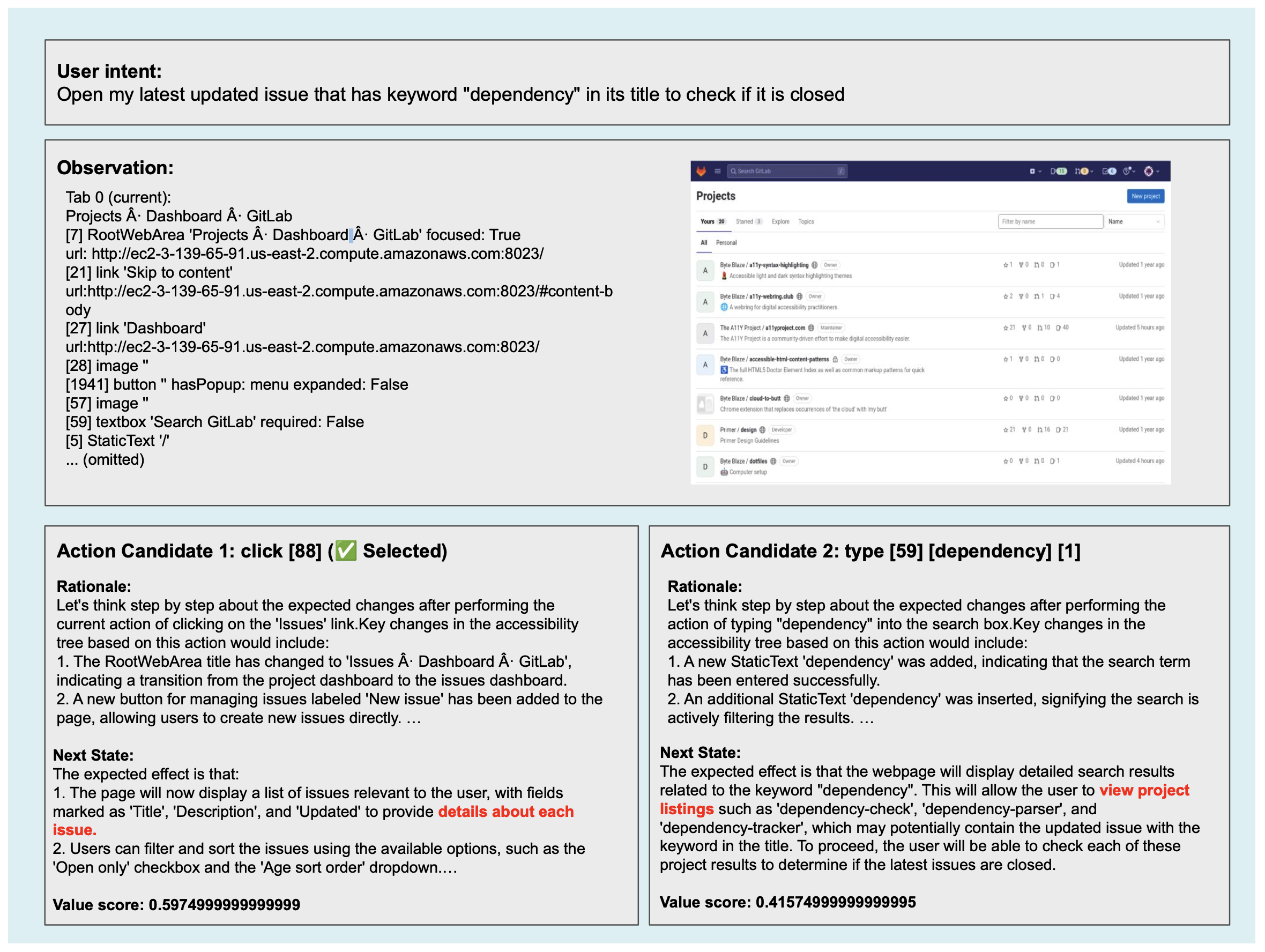
WMA web agent successfully inferences on Gitlab domain in the WebArena benchmark (instance #175). Using the policy model (i.e., GPT-4o), WMA web agent selects the most proper action click [88] by leveraging its learned environment dynamics.
@inproceedings{chae2024web,
title={Web agents with world models: Learning and leveraging environment dynamics in web navigation},
author={Chae, Hyungjoo and Kim, Namyoung and Ong, Kai Tzu-iunn and Gwak, Minju and Song, Gwanwoo and Kim, Jihoon and Kim, Sunghwan and Lee, Dongha and Yeo, Jinyoung},
booktitle={The Thirteenth International Conference on Learning Representations}
}